探索怪谈竞赛中文章作者与评分者Karma等级分布之间的统计相关性:有序多类别逻辑回归分析
引言:
随着怪谈竞赛的落幕,一个有趣的问题可以被提出:文章作者的Karma等级与评分者的Karma等级分布之间是否存在统计学相关性。本文将采用怪谈竞赛的全部参赛作品作为研究样本,进行探索性数据分析,检验评分者的Karma等级与作者的Karma等级之间的关联性。
获取样本:
通过Wikidot的listpage模块以及基于Python的爬虫操作,我们收集了作者的Karma等级、作品页面链接及评分者的Karma等级信息,并将这些数据导出为CSV格式以便进行后续分析。数据收集分为以下两步:
import random
import string
from fake_useragent import UserAgent
import requests
import time
import re
NUM_THREADS = 30
def getHTML(link):
rHeader = {
'User-Agent': f'{UserAgent().random}',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://scp-wiki-cn.wikidot.com/',
}
requestRes = requests.get(link,headers=rHeader)
return requestRes
def postHTML(link, data):
header = {
"User-Agent": f'{UserAgent().random}',
"Content-Type": "application/x-www-form-urlencoded",
"Referer": "https://scp-wiki-cn.wikidot.com/",
}
session = requests.Session()
url = 'https://scp-wiki-cn.wikidot.com/ajax-module-connector.php'
session.cookies.set('wikidot_token7', token, domain='scp-wiki-cn.wikidot.com', path='/')
response = session.post(url, headers= header, data=data).json()["body"]
return response
def getAuthurAndLink(mainRes):
div_pattern = re.compile(r'<div class="list-pages-box">\s*<p>(.*?)\s*</div>', re.DOTALL)
div_table = re.findall(div_pattern,mainRes)[0]
info_pattern = re.compile(r'<a href="(/[^"]+)">([^<]+)</a>.*?<a href="(http://www.wikidot.com/user:info/[^"]+)"[^>]+>([^<]+)</a>.*?(\d+)')
info_match = re.findall(info_pattern,div_table)
searchDictList = []
verifyDictList = []
for link, title, userlink, username, score in info_match:
searchDict = {"link": "https://scp-wiki-cn.wikidot.com"+link, "userlink": userlink}
verifyDict = {"title": title, "username": username.replace(" ",""), "score": score}
searchDictList.append(searchDict)
verifyDictList.append(verifyDict)
return searchDictList,verifyDictList
mainRes = getHTML("https://scp-wiki-cn.wikidot.com/eddy-sandbox-1")
searchDictList,verifyDictList = getAuthurAndLink(mainRes.text)
karmaList = ["none", "low", "medium", "high", "veryhigh", "guru"]
token = ''.join(random.choice(string.ascii_lowercase + string.digits) for _ in range(10))
globalKarma = {}
import threading
from concurrent.futures import ThreadPoolExecutor
def getKarma(userLink,expectUserName):
if expectUserName in globalKarma.keys():
print(f"Output User {expectUserName} of Karma {globalKarma[expectUserName]}")
return globalKarma[expectUserName]
else:
requestRes = getHTML(userLink)
pattern = re.compile(r'<h1 class="profile-title">\s*<img [^>]+>\s*([^\n]+)\s*</h1>.*?<dt>Karma level:</dt>\s*<dd>\s*([^<]+)', re.DOTALL)
match = re.search(pattern,requestRes.text)
foundUserName, karma = match.groups()
foundUserName = foundUserName.replace(" ","")
karma = karma.replace(" ","")
if(foundUserName != expectUserName):
print(f"{foundUserName} != {expectUserName}")
if not(karma in karmaList):
print(f"Given level {karma} not valid")
time.sleep(1)
globalKarma[expectUserName] = karma
print(f"Record User {expectUserName} of Karma {karma}")
return karma
def getVoterList(pageLink,expectVoterNum):
requestsRes = getHTML(pageLink)
pattern = re.compile(r'WIKIREQUEST.info.pageId = (.*?);', re.DOTALL)
pageId = re.search(pattern, requestsRes.text).group(1)
data = {
'wikidot_token7': token,
'pageId': pageId,
'moduleName': 'pagerate/WhoRatedPageModule'
}
votersHtml = postHTML(pageLink,data)
votersPattern = re.compile(r'<a href="(http://www.wikidot.com/user:info/[^"]+)"[^>]*>([^<]+)</a></span>\s*<span style="color:#777">\s*([+-])', re.DOTALL)
deleteNum = votersHtml.count('deleted')
user_ratings = votersPattern.findall(votersHtml)
time.sleep(1)
return user_ratings
def process_author(inputTupel):
searchDict,verifyDict = inputTupel
print(f'Processing {verifyDict["username"]}')
authorDict = {
"authorKarma": getKarma(searchDict["userlink"], verifyDict["username"]),
"none_upvote": 0, "none_downvote": 0,
"low_upvote": 0, "low_downvote": 0,
"medium_upvote": 0, "medium_downvote": 0,
"high_upvote": 0, "high_downvote": 0,
"veryhigh_upvote": 0, "veryhigh_downvote": 0,
"guru_upvote": 0, "guru_downvote": 0,
"link": searchDict["link"]
}
votersList = getVoterList(searchDict["link"], verifyDict["score"])
for voterLink, voterName, vote in votersList:
voterKarma = getKarma(voterLink, voterName.replace(" ", ""))
vote_type = "upvote" if vote == '+' else "downvote"
karma_key = f"{voterKarma}_{vote_type}"
if karma_key in authorDict:
authorDict[karma_key] += 1
else:
print(f"Unrecognized karma level or vote type: {karma_key}")
return authorDict
infoDictList = []
with ThreadPoolExecutor(max_workers=NUM_THREADS) as executor:
infoDictList += list(executor.map(process_author, zip(searchDictList, verifyDictList)))
数据介绍:
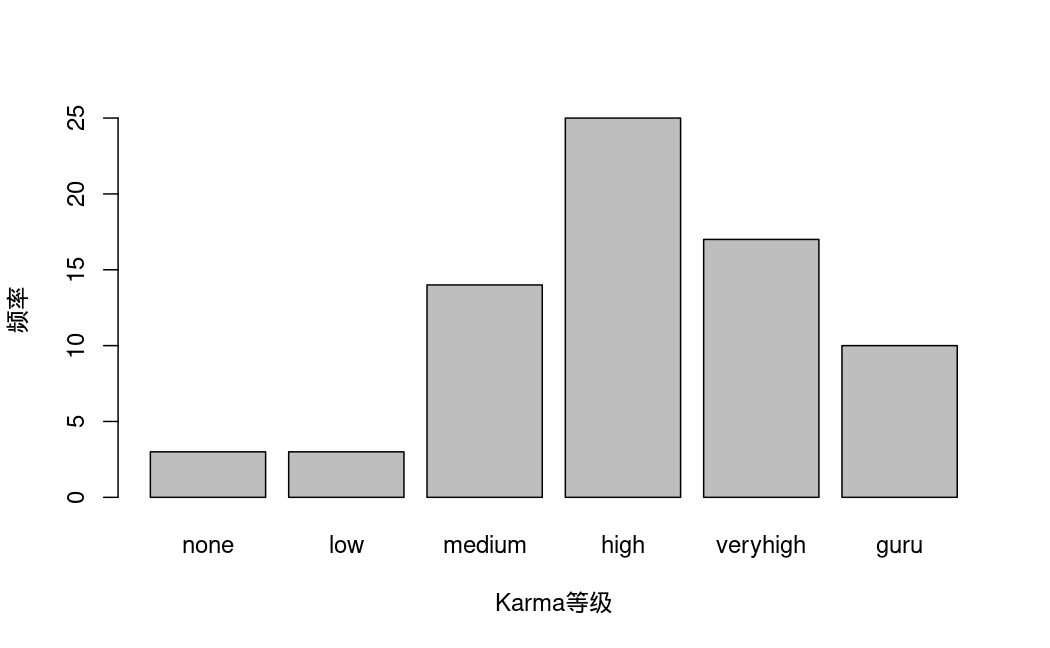
本数据集包含72个作品的相关信息,记录了以下变量(1个类别变量和6个定量变量):
- authorKarma: 作者的Karma等级,共为6种(无,低,中,高,非常高,宗师)
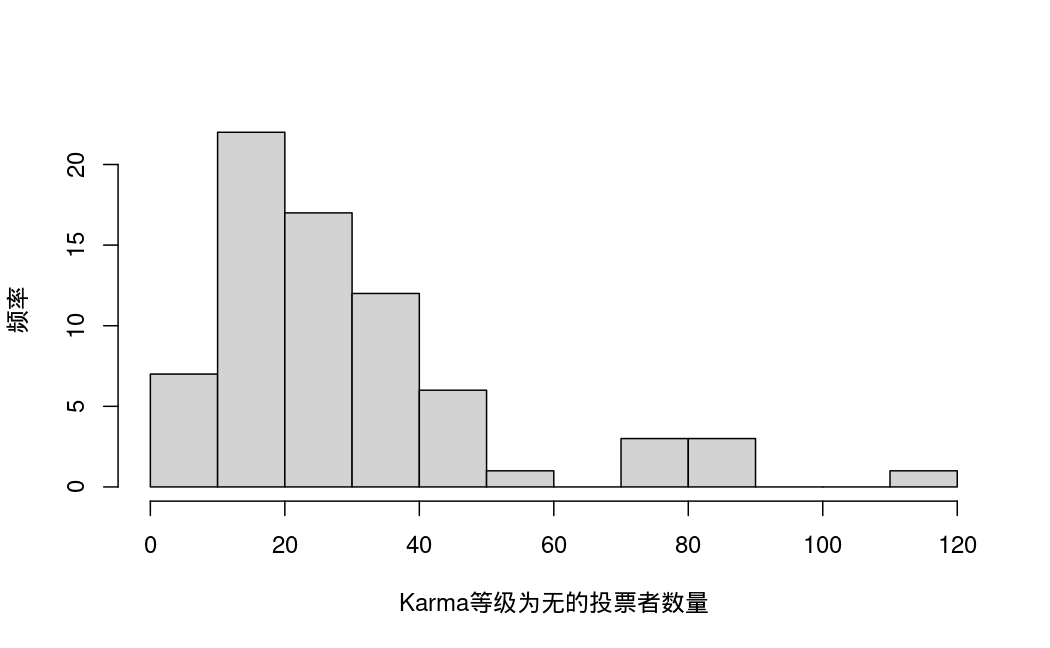
- none: 投票者中Karma等级为无的数量。
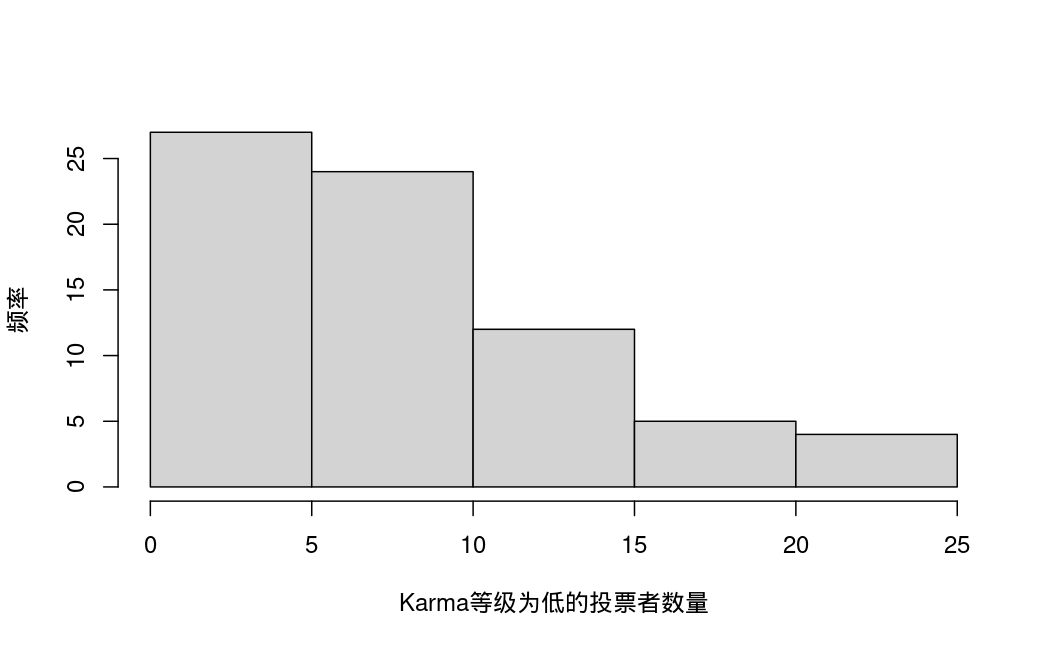
- low:投票者中Karma等级为低的数量。
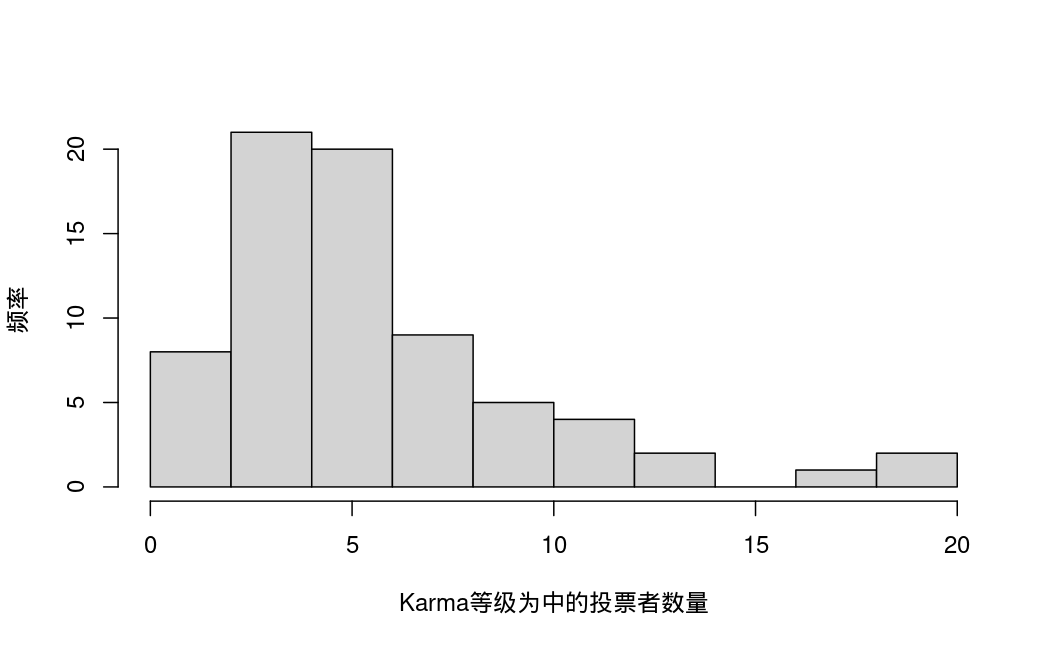
- medium:投票者中Karma等级为中的数量。
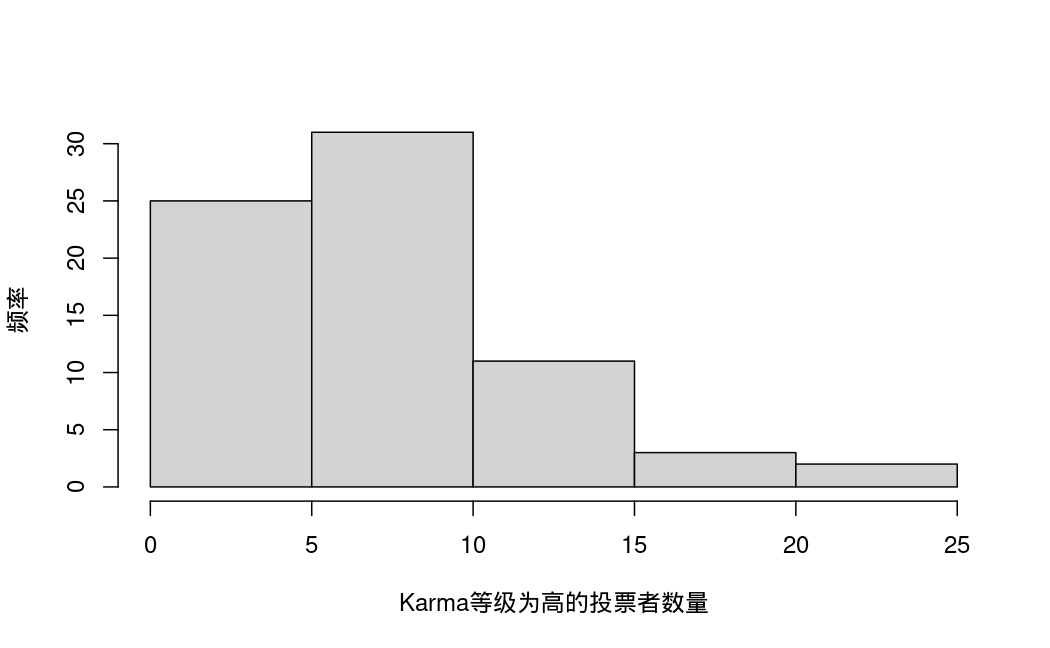
- high:投票者中Karma等级为高的数量
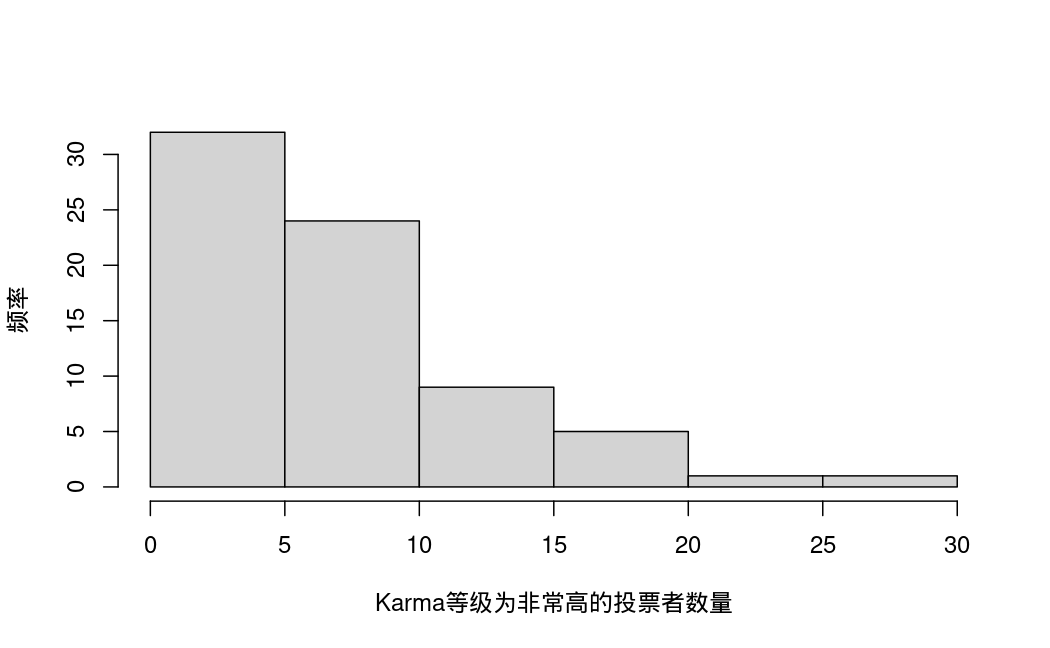
- veryhigh:投票者中Karma等级为非常高的数量。
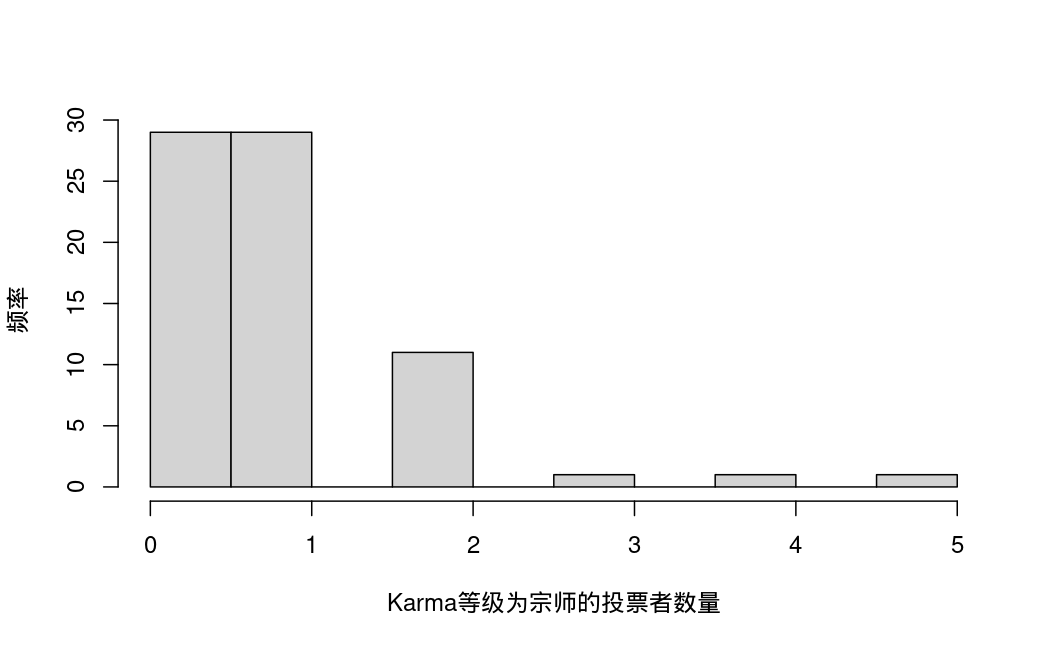
- guru:投票者中Karma等级为宗师的数量
为了从评分者的Karma等级分布推断作者的Karma等级,作者的Karma等级将作为因变量,其余的定量变量作为自变量。
单变量描述性统计:
构建统计模型:
当样本中的因变量为类别变量时,逻辑回归模型是一种有效的建模方式。考虑到Karma等级是一系列有序的类别,我们将选择有序多类别逻辑回归模型进行数据探索分析。以下使用R语言进行实现:
导入模型并确保类别变量的有序性:
cpRes2 <- readr::read_csv("SCPresult2.csv")
cpRes2$karma_factored <- factor(cpRes2$authorKarma,
levels=c("none", "low", "medium","high","veryhigh","guru"),
ordered=TRUE)
cpModel2 <- polr(karma_factored ~ none + low + medium + high + veryhigh + guru, data = cpRes2, Hess=TRUE, method="logistic", control = list(maxit = 50, reltol = 1e-5))
模型的数学表达:
设因变量为Y,有序多类别逻辑回归模型的形式为:
(1)
\begin{align} Y = \left\{ \begin{array}{lr} 分类 C (最高) & \\ 分类 C -1 &\\ ... &\\ 分类 2 &\\ 分类 1 (最低) \end{array} \right. \end{align}
定义累计概率模型为:$P(Y\leq j)$对于 $j = 1, 2, ...., c -1$:
(2)
\begin{align} P(Y\leq 1) &= P(Y=1) \\ P(Y\leq 2) &= P(Y=1 \text{ or } Y=2) \\ &.... \\ P(Y\leq c-1) &= P(Y=1 \text{ or } Y=2 \text{ or }... \text{ or } Y= c-1) \end{align}
由此,当自变量为$X_1, X_2, .... X_k$时,可得以下模型:
(3)
\begin{align} \log(\frac{P(Y\leq 1)}{P(Y>1)}) &= \beta^{(1)}_0 + \beta_1X_1 + \beta_2X_2 + .... + \beta_kX_k \\ \log(\frac{P(Y\leq 2)}{P(Y>2)})&= \beta^{(2)}_0 + \beta_1X_1 + \beta_2X_2 + .... + \beta_kX_k \\ &...\\ \log(\frac{P(Y\leq c-1)}{P(Y>c-1)}) &= \beta^{(c-1)}_0 + \beta_1X_1 + \beta_2X_2 + .... + \beta_kX_k \end{align}
模型统计:
系数:
值 标准误差 t值
none 0.03636 0.02946 1.2340
low -0.01126 0.09545 -0.1180
medium -0.27223 0.13023 -2.0903
high -0.03265 0.09991 -0.3268
veryhigh 0.25541 0.10082 2.5334
guru 0.39791 0.28777 1.3827
截距:
值 标准误差 t值
none|low -2.4281 0.7291 -3.3303
low|medium -1.6682 0.6071 -2.7480
medium|high -0.0908 0.5020 -0.1808
high|veryhigh 1.7864 0.5265 3.3928
veryhigh|guru 3.7467 0.7131 5.2540
残差离差: 194.5533
AIC: 216.5533
建立模型:
注意到预测变量的值应取反,考虑到R语言实现polr函数时的具体实现。定义:
| $X_1$ |
$X_2$ |
$X_3$ |
$X_4$ |
$X_5$ |
$X_6$ |
| "无"的数量 |
"低"的数量 |
"中"的数量 |
"高"的数量 |
"非常高"的数量 |
"宗师"的数量 |
(4)
\begin{align} \log(\frac{P(Y\leq 无)}{P(Y>无)}) &= -2.428 + -0.036X_1+ 0.011X_2 + 0.272X_3 + 0.033X_4 + -0.255X_5 + -0.398X_6\\ \log(\frac{P(Y\leq 低)}{P(Y>低)}) &= -1.6682 + -0.036X_1+ 0.011X_2 + 0.272X_3 + 0.033X_4 + -0.255X_5 + -0.398X_6 \\ \log(\frac{P(Y\leq 中)}{P(Y>中)}) &= -0.0908 + -0.036X_1+ 0.011X_2 + 0.272X_3 + 0.033X_4 + -0.255X_5 + -0.398X_6 \\ \log(\frac{P(Y\leq 高)}{P(Y>高)}) &= 1.7864 + -0.036X_1+ 0.011X_2 + 0.272X_3 + 0.033X_4 + -0.255X_5 + -0.398X_6 \\ \log(\frac{P(Y\leq 非常高)}{P(Y>非常高)}) &= 3.7467 + -0.036X_1+ 0.011X_2 + 0.272X_3 + 0.033X_4 + -0.255X_5 + -0.398X_6 \end{align}
检验模型:
平行性检验:确保自变量在不同的回归方程中对因变量的影响是一致的。
- 无效假设($H0$):满足平行性检验。
- 备择假设($HA$):不满足平行性检验。
输出如下:
--------------------------------------------
Test for X2 df probability
--------------------------------------------
Omnibus 18.51 24 0.78
none 0.83 4 0.93
low 2.53 4 0.64
medium 4.4 4 0.35
high 3.67 4 0.45
veryhigh 2.82 4 0.59
guru 3.08 4 0.54
--------------------------------------------
注意到概率下全部项均大于预先假设的显著性水平(0.05),故不存在显著的证据表明无效假设被拒绝,即模型通过了平行性检验。
显著性检验:通过方差分析,比较只含截距的模型与完整模型间的差异,验证模型的预测能力。
- 无效假设($H0$):两个模型间的平均数的差异不显著(没有区别)
- 备择假设($HA$):显著(存在区别)
输出如下:
Likelihood ratio tests of ordinal regression models
Response: karma_factored
Model Resid. df Resid. Dev
1 1 67 225.4382
2 none + low + medium + high + veryhigh + guru 61 194.5533
Test Df LR stat. Pr(Chi)
1
2 1 vs 2 6 30.88489 2.666474e-05
因p值远远低于0.05,故拒绝无效假设,即原模型具备统计学意义。
分析:
注意到Karma等级为“中”和“非常高”的数量对于因变量的预测具备显著性 。通过计算累计优势比,我们可以评估解释变量对有序响应变量的影响强度和方向:
| Karma等级为"中”的数量的回归系数 |
累计优势比 |
统计学分析 |
结论 |
| 0.27223 |
$\text e^{0.27223} = 1.312889$ |
在控制了其他相关因素(除了'中'以外的所有解释变量)的情况下,我们预估对于一个作品,Karma等级为‘中’的评分者每增加一名,与给定等级相比,不超过任何给定等级的累计优势比平均为之前的1.312889倍。 |
Karma等级“中”的评分者的增加将降低该作品作者具备更高Karma等级的概率。 |
| Karma等级为"非常高”的数量的回归系数 |
累计优势比 |
统计学分析 |
结论 |
| -0.25541 |
$\text e^{-0.25541} = 0.7745988$ |
在控制了其他相关因素(除了'非常高'以外的所有解释变量)的情况下,我们预估对于一个作品,Karma等级为‘非常高’的评分者每增加一名,与给定等级相比,不超过任何给定等级的累计优势比平均为之前的0.7745988倍。 |
Karma等级“非常高”的评分者的增加将增加该作品作者具备更高Karma等级的概率。 |
对比:
在统计了cn3000, cn2000, cn1000, 2024冬季征文,2023冬季征文,2023夏季征文,2022冬季征文,2022夏季征文,2022电子游戏竞赛,2023撕咬竞赛等竞赛的全部484个具备有效账户作者的参赛作品后。我们基于该数据集和已有统计方法,构建了一个有效并符合检验条件的模型。
Call:
polr(formula = karma_factored ~ none + low + medium + high +
veryhigh + guru, data = cpCompareRes, Hess = TRUE, method = "logistic")
Coefficients:
Value Std. Error t value
none 0.0007420 0.004123 0.1799
low -0.0302076 0.029411 -1.0271
medium -0.0001873 0.018728 -0.0100
high -0.0224676 0.020102 -1.1177
veryhigh 0.1036817 0.017584 5.8963
guru 0.0232437 0.042801 0.5431
Intercepts:
Value Std. Error t value
none|low -3.2861 0.3693 -8.8986
low|medium -2.4436 0.2593 -9.4224
medium|high -1.1063 0.1720 -6.4303
high|veryhigh 0.8522 0.1535 5.5526
veryhigh|guru 3.1637 0.2189 14.4530
Residual Deviance: 1230.326
AIC: 1252.326
显著性测试表明,在当前显著性水平下,仅Karma等级为"非常高”的数量在预测作者的Karma等级时具备显著性:在控制了其他相关因素(除了'非常高'以外的所有解释变量)的情况下,我们预估对于一个作品,Karma等级为‘非常高’的评分者每增加一名,与给定等级相比,不超过任何给定等级的累计优势比平均为之前的0.9015122倍。
由此,我们可以发现在该数据集中,相对于其他Karma等级,"非常高"级别的评分者的数量对预测作者Karma等级的影响较小。即与原数据集(怪谈竞赛数据集)相比,"非常高"级别评分者的增加对提高作者达到更高Karma等级的概率的幅度的降低。
不难发现,怪谈数据集与该数据集的回归系数具备相同的符号项,表明尽管两者在统计学意义上的影响幅度不同,影响的方向是一致的,可能反映了不同数据集(环境)下影响趋势的稳定性。
结论:
本文探讨了怪谈竞赛中作品的作者Karma等级与评分者Karma等级分布之间的关联性。通过有序多类别逻辑回归分析,我们发现,Karma等级为“中”和“非常高”的评分者数量对作者Karma等级的预测具有统计学意义:当一个作品的评分者中,拥有“中”Karma等级的评分者数量增加时,作者具备更高Karma等级的概率降低;而“非常高”Karma等级的评分者数量增加时,该概率增加。
这一分析揭示了评分者Karma等级分布与作者Karma等级之间的潜在相关性,但我们必须认识到,相关性并不等同于因果关系。此外,考虑到数据集规模相对较小,所得出的模型推断可能受到样本选择的限制,其外推性需要谨慎对待。此分析的结果应被视为初步的,它为未来在更大规模和更广泛样本上进行研究提供了理论基础和动机。